It is easy to change the layout, sort, reindex, rename, and subset table data using pandas commands. The simple code below shows you how to do this easily. The functions include melt(),pivot,sort_values,rename,sort_index,drop,filter,query,iloc,loc,iat,at and drop_duplicates.
Table of Contents
Prepare data
#dowonload https://github.com/ziwangdeng/Data/blob/main/Vancouver_weather2010to2019_v00.csv
import pandas as pd
df=pd.read_csv('Vancouver_weather2010to2019_v00.csv')
cols=df.columns
df1=df[cols[:10]]
df2=df[cols[10:]]
ll=len(df)
df3=df.head(5000)
df4=df.tail(ll-5000)
df.columns
Index(['Unnamed: 0', 'Longitude (x)', 'Latitude (y)', 'Station Name',
'Climate ID', 'Date/Time (LST)', 'Year', 'Month', 'Day', 'Time (LST)',
'Temp (°C)', 'Temp Flag', 'Dew Point Temp (°C)', 'Dew Point Temp Flag',
'Rel Hum (%)', 'Rel Hum Flag', 'Precip. Amount (mm)',
'Precip. Amount Flag', 'Wind Dir (10s deg)', 'Wind Dir Flag',
'Wind Spd (km/h)', 'Wind Spd Flag', 'Visibility (km)',
'Visibility Flag', 'Stn Press (kPa)', 'Stn Press Flag', 'Hmdx',
'Hmdx Flag', 'Wind Chill', 'Wind Chill Flag', 'Weather'],
dtype='object')
Collect columns into rows
pd.melt(df).sample(n=10)
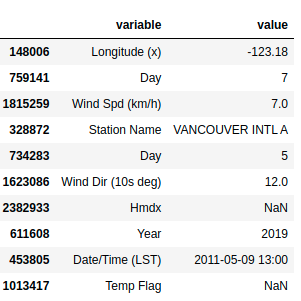
Spread rows into columns
df.pivot(columns='Month', values='Temp (°C)').sample(n=10)

Append rows of DataFrames
pd.concat([df3,df4])
df3.append(df4,ignore_index=True)
df3.shape
(5000, 31)
df4.shape
(83392, 31)
pd.concat([df3,df4]).shape
(88392, 31)
Append columns of DataFrames
pd.concat([df1,df2], axis=1)
df1.shape
(88392, 10)
df2.shape
(88392, 21)
pd.concat([df1,df2], axis=1).shape
(88392, 31)
Drop columns from DataFrame
df.drop(columns=['Unnamed: 0', 'Longitude (x)', 'Latitude (y)', 'Station Name'])
Subset columns of DataFrames
Select columns whose name matches regular expression regex
df[['Longitude (x)', 'Latitude (y)', 'Station Name']]
#Select columns whose name matches regular expression regex
df.filter(regex='^T')
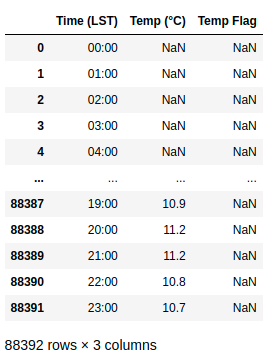
Select columns using iloc
df.iloc[:, [0, 10, 20, 25]]
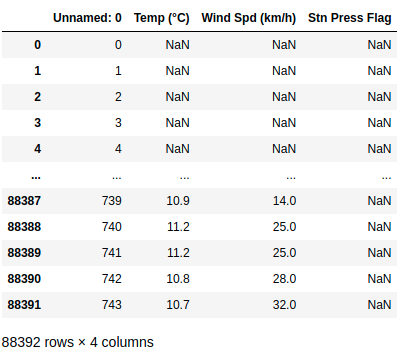
Select columns between 2 columns
df.loc[:, 'Time (LST)':'Dew Point Temp Flag']
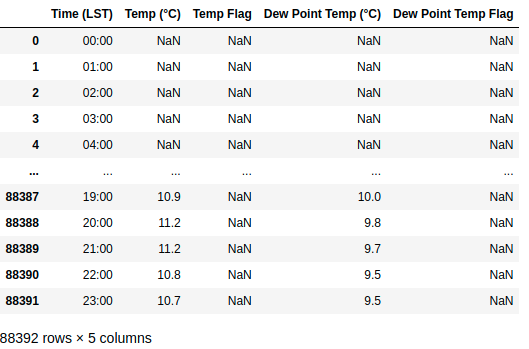
Order rows by values of a column
df.sort_values('Temp (°C)')
df.sort_values('Temp (°C)', ascending=True)
df.sort_values('Temp (°C)', ascending=False)
Subset rows
Extract rows that meet logical criteria.
df[df.Year > 2019]
Remove duplicate rows
df.drop_duplicates()
Select rows using query
df.query('Year >2019')
df.query('Year > 2019 and Day < 10')
Select rows based on index
df.iloc[10:20]
df.iloc[:10]
df.iloc[10:]
df.iloc[[1,5,100]]
Subset rows and columns
df.loc[df['Year'] > 2019, ['Time (LST)','Dew Point Temp (°C)']]
Access single value by index
df.iat[10, 5]
df.at[4, 'Year']
Set index with a column
df.set_index('Date/Time (LST)')
Set MultiIndex for Pandas DataFrame
df.set_index(['Date/Time (LST)','Weather'])
Sort the index of a DataFrame
df.sort_index()
Reset index of DataFrame to row numbers, moving index to columns.
df.reset_index()
Rename the columns of a DataFrame
df.rename(columns = {'Temp (°C)':'Tas','Wind Spd (km/h)':'Wsp'})
