Example code for identifying and selecting the high predictive performance features from dataset for machine learning and deep learning models. It can also answer the following questions:
- How to directly read weather data from a website?
- How to select most important features from dataset based on various methods?
Table of Contents
Prepare data
Code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# create range of monthly dates
download_dates = pd.date_range(start='2019-01-01', end='2020-01-01', freq='MS')
# URL from Chrome DevTools Console
base_url = ("https://climate.weather.gc.ca/climate_data/bulk_data_e.html?format=csv&"
"stationID=51442&Year={}&Month={}&Day=7&timeframe=1&submit=Download+Data") # add format option to year and month
# create list of remote URL from base URL
list_of_url = [base_url.format(date.year, date.month) for date in download_dates]
# download and combine multiple files into one DataFrame
df = pd.concat((pd.read_csv(url) for url in list_of_url))
keepcolumns=['Date/Time (LST)','Longitude (x)','Year', 'Month', 'Day','Temp (°C)','Dew Point Temp (°C)','Hmdx','Wind Spd (km/h)']
data=df[keepcolumns]
data=data.rename(columns={'Date/Time (LST)':'dt_var','Temp (°C)':'T','Dew Point Temp (°C)':'Td',
'Longitude (x)':'Lat','Wind Spd (km/h)':'wind'
})
datetime_series = pd.to_datetime(data['dt_var'])
datetime_index = pd.DatetimeIndex(datetime_series.values)
data1=data.set_index(datetime_index)
data1.drop('dt_var',axis=1,inplace=True)
data=data1.head(100)
Drop some features
from feature_engine.selection import DropFeatures
# set up the transformer
transformer = DropFeatures(
features_to_drop=['wind', 'Year', 'Month', 'Hmdx']
)
# fit the transformer
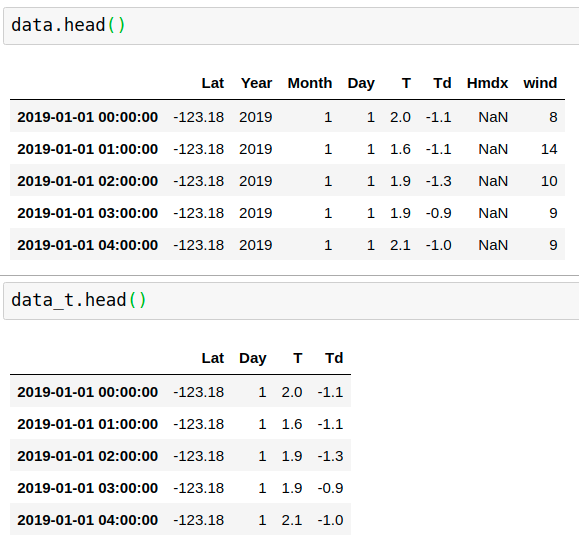
transformer.fit(data)
data_t = transformer.transform(data)
Drop constant features
It will not drop column with all values NaN. NaN should be remove if with out “missing_values=’ignore’ “
data=data1.copy()
from feature_engine.selection import DropConstantFeatures
# set up the transformer
transformer = DropConstantFeatures(tol=0.7, missing_values='ignore')
# fit the transformer
transformer.fit(data)
data_t = transformer.transform(data)

data=data1.copy()
from feature_engine.selection import DropConstantFeatures
# set up the transformer
transformer = DropConstantFeatures(tol=0.7)
# fit the transformer
transformer.fit(data)
data_t = transformer.transform(data)
Drop Duplicate Features
Finds and removes duplicated variables from a dataframe.
data=data1.copy()
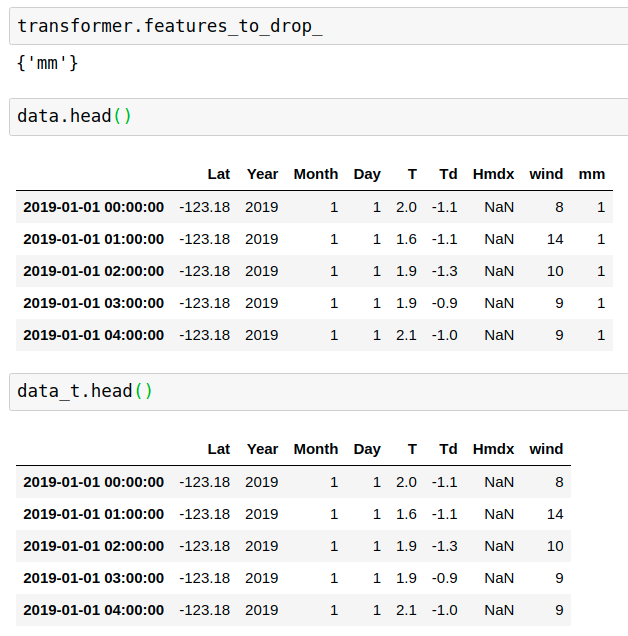
data['mm']=data['Month']
from feature_engine.selection import DropDuplicateFeatures
# set up the transformer
transformer = DropDuplicateFeatures()
# fit the transformer
transformer.fit(data)
data_t = transformer.transform(data)
Drop Correlated Features
Finds and removes correlated variables from a dataframe.Features are removed on first found first removed basis, without any further insight.
data=data1.copy()
data['mm']=data['Month']
from feature_engine.selection import DropCorrelatedFeatures
# set up the transformer
transformer = DropCorrelatedFeatures(variables=None, method='pearson', threshold=0.8)
# fit the transformer
transformer.fit(data)
data_t = transformer.transform(data)

Smart Correlated Selection
For situations that have 3, 4 or more features that are correlated. Thus, which one should be keep and which ones should we drop.
This method will retain the one with:
- the highest variance
- the highest cardinality
- the least missing data
- the most important (based on embedded selection methods)
And drop the rest.
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
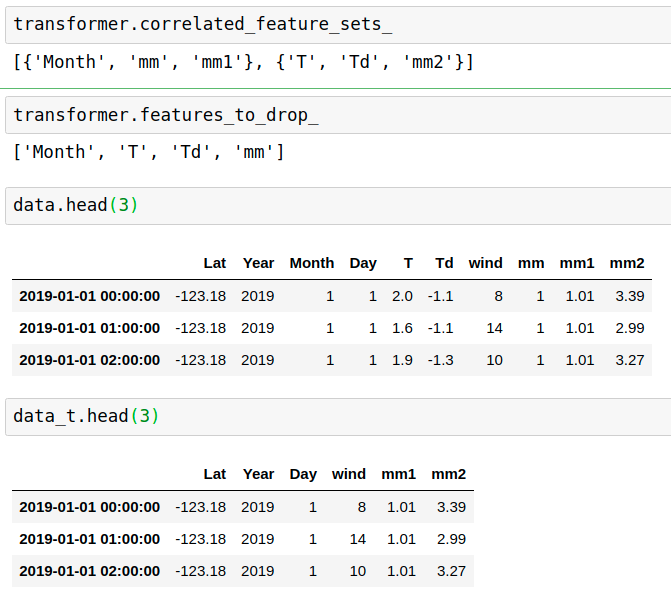
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['mm']+data['T']+0.5+data['Td']*0.1
from feature_engine.selection import SmartCorrelatedSelection
# set up the transformer
transformer = DropCorrelatedFeatures(variables=None, method='pearson', threshold=0.8)
# fit the transformer
transformer.fit(data)
data_t = transformer.transform(data)
Select by single feature’s performance
Select features based on the performance of machine learning models trained using individual features.
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['mm']+data['T']+0.5+data['Td']*0.1
X=pd.DataFrame(data['T'])
Y=pd.DataFrame(data['Td'])
from sklearn.linear_model import LinearRegression
from feature_engine.selection import SelectBySingleFeaturePerformance
# set up the transformer
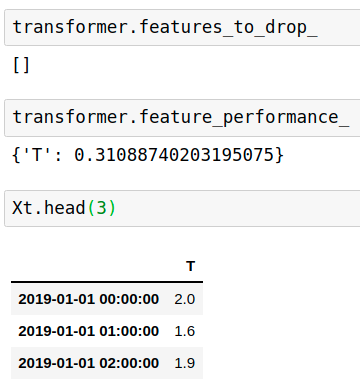
transformer = SelectBySingleFeaturePerformance(
estimator=LinearRegression(), scoring="r2", cv=3, threshold=0.3)
# fit the transformer
transformer.fit(X,Y)
Xt = transformer.transform(X)
Change the threshold to 0.4, then variable T is dropped.

Recursive Feature Elimination
A feature will be kept or removed based on the performance of a machine learning model without that feature.
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['T']+0.5+data['Td']*0.1
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'wind', 'mm', 'mm1', 'mm2']])
Y=pd.DataFrame(data['Td'])
from sklearn.linear_model import LinearRegression
from feature_engine.selection import RecursiveFeatureElimination
# initialize linear regresion estimator
linear_model = LinearRegression()
# set up the transformer
transformer = RecursiveFeatureElimination(estimator=linear_model, scoring="r2", cv=3)
# fit the transformer
transformer.fit(X,Y)
Xt = transformer.transform(X)

Recursive Feature Addition
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['T']+0.5+data['Td']*0.1
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'wind', 'mm', 'mm1', 'mm2']])
Y=pd.DataFrame(data['Td'])
from sklearn.linear_model import LinearRegression
from feature_engine.selection import RecursiveFeatureAddition
# initialize linear regresion estimator
linear_model = LinearRegression()
# set up the transformer
transformer = RecursiveFeatureAddition(estimator=linear_model, scoring="r2", cv=3)
# fit the transformer
transformer.fit(X,Y)
Xt = transformer.transform(X)
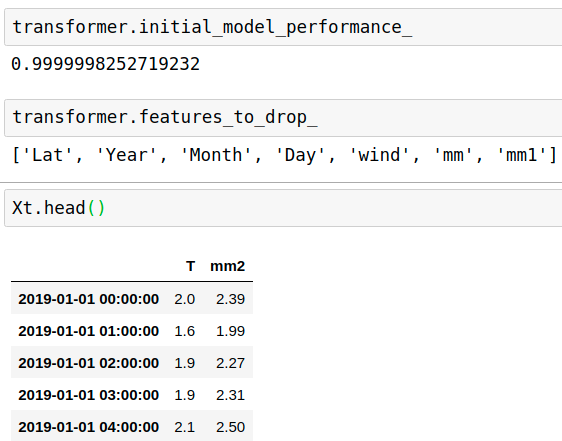
Select features by shuffling
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['T']+0.5+data['Td']*0.1
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'wind', 'mm', 'mm1','mm2']])
Y=pd.DataFrame(data['Td'])
from sklearn.linear_model import LinearRegression
from feature_engine.selection import SelectByShuffling
# initialize linear regresion estimator
linear_model = LinearRegression()
# set up the transformer
transformer = SelectByShuffling(estimator=linear_model, scoring="r2", cv=3)
# fit the transformer
transformer.fit(X,Y)
Xt = transformer.transform(X)

Select features by target mean performance
Selects features based on performance metrics like the ROC-AUC or accuracy for classification, or mean squared error and R-squared for regression.
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['T']+0.5+data['Td']*0.1
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2']])
Y=pd.DataFrame(data['wind'])
Y.loc[Y['wind']<10,'wind']=0
Y.loc[Y['wind']>0,'wind']=1
from sklearn.linear_model import LinearRegression
from feature_engine.selection import SelectByTargetMeanPerformance
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
test_size=0.1,
random_state=0)
# set up the transformer
transformer = SelectByTargetMeanPerformance(
variables=None,
scoring="roc_auc",
threshold=None,
bins=3,
strategy="equal_frequency",
cv=3,
regression=False,
)
# fit the transformer
transformer.fit(X,Y)
Xt = transformer.transform(X)
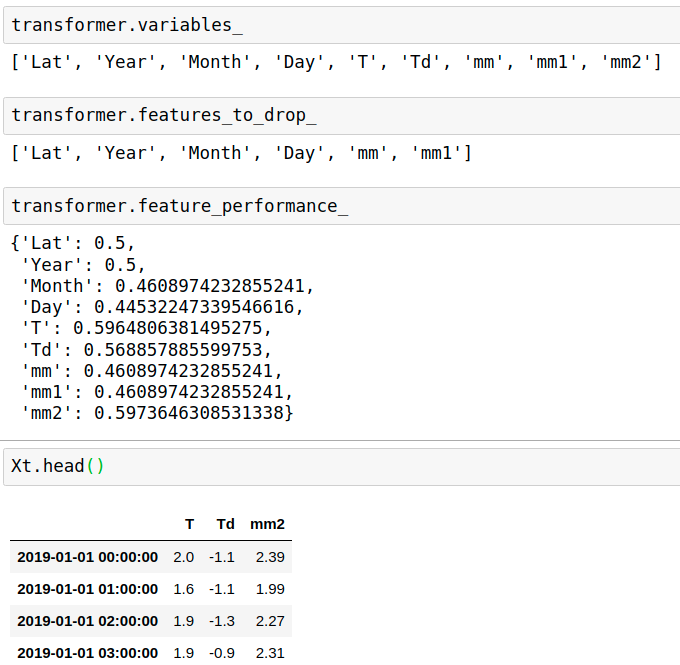
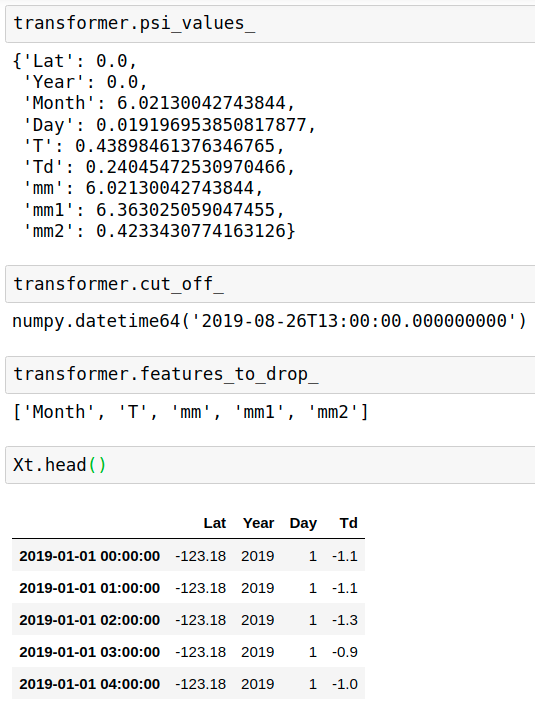
Drop High Population Stability Index (PSI) features
Find and remove features with changes in their distribution, i.e. “unstable values”, from a pandas dataframe.
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['T']+0.5+data['Td']*0.1
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2']])
from feature_engine.selection import DropHighPSIFeatures
transformer = DropHighPSIFeatures(split_frac=0.6)
transformer.fit(X)
Xt = transformer.transform(X)
Select features by Information value
Select features based on whether the feature’s information value score is greater than the threshold passed by the user.


data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01
data['mm2']=data['T']+0.5+data['Td']*0.1
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2']])
Y=pd.DataFrame(data['wind'])
Y.loc[Y['wind']<10,'wind']=0
Y.loc[Y['wind']>0,'wind']=1
from feature_engine.selection import SelectByInformationValue
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
test_size=0.1,
random_state=0)
# set up the transformer
transformer = SelectByInformationValue(
bins=5,
strategy="equal_frequency",
threshold=0.2,
)
# fit the transformer
transformer.fit(X_train,Y_train)
Xt = transformer.transform(X)
