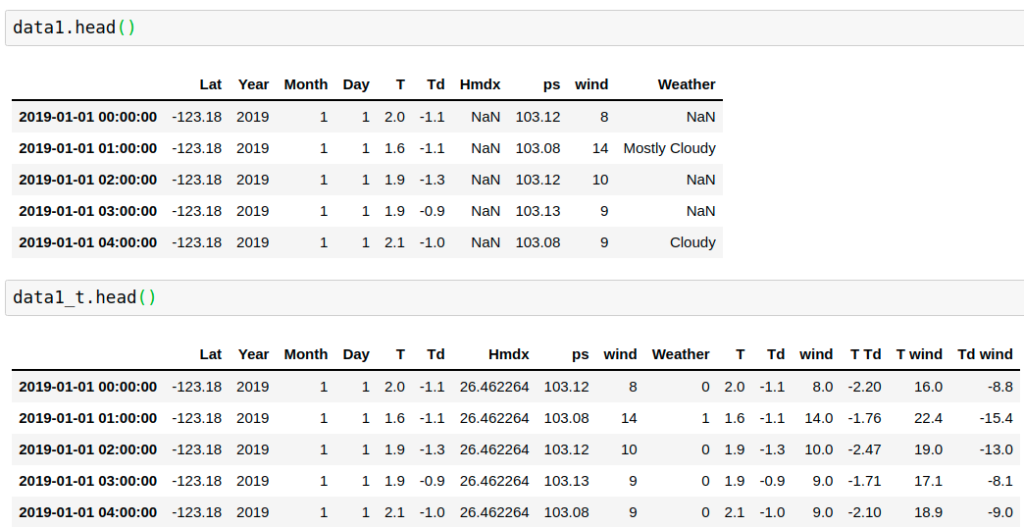
Example code for transforming a selected group of variables with Sklearn Transformer Wrapper. It can also answer following questions:
- How to directly read weather data from Canadian government website?
Table of Contents
Prepare data sample
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
from feature_engine.encoding import RareLabelEncoder
from feature_engine.imputation import CategoricalImputer, MeanMedianImputer
from feature_engine.encoding import OrdinalEncoder
from sklearn.preprocessing import KBinsDiscretizer
from sklearn.impute import SimpleImputer
from sklearn.feature_selection import (
f_regression,
SelectKBest,
SelectFromModel,
)
from sklearn.linear_model import Lasso
from feature_engine.wrappers import SklearnTransformerWrapper
# create range of monthly dates
download_dates = pd.date_range(start='2019-01-01', end='2020-01-01', freq='MS')
# URL from Chrome DevTools Console
base_url = ("https://climate.weather.gc.ca/climate_data/bulk_data_e.html?format=csv&"
"stationID=51442&Year={}&Month={}&Day=7&timeframe=1&submit=Download+Data") # add format option to year and month
# create list of remote URL from base URL
list_of_url = [base_url.format(date.year, date.month) for date in download_dates]
# download and combine multiple files into one DataFrame
df = pd.concat((pd.read_csv(url) for url in list_of_url))
keepcolumns=['Date/Time (LST)','Longitude (x)','Year', 'Month', 'Day','Temp (°C)','Dew Point Temp (°C)','Hmdx','Wind Spd (km/h)']
data=df[keepcolumns]
data=data.rename(columns={'Date/Time (LST)':'dt_var','Temp (°C)':'T','Dew Point Temp (°C)':'Td',
'Longitude (x)':'Lat','Wind Spd (km/h)':'wind'
})
datetime_series = pd.to_datetime(data['dt_var'])
datetime_index = pd.DatetimeIndex(datetime_series.values)
data1=data.set_index(datetime_index)
data1.drop('dt_var',axis=1,inplace=True)
OneHotEncoder
data1=data.copy()
data1[data1['wind']<10]=0
data1[data1['wind']>30]=2
data1[data1['wind']>2]=1
ohe = SklearnTransformerWrapper(
OneHotEncoder(sparse=False, drop='first'),
variables = ['wind'])
ohe.fit(data1)
data1_t = ohe.transform(data1)
SimpleImputer
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
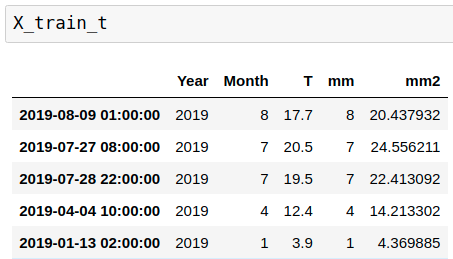
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01+np.random.normal(0, 1, data['T'].shape)
data['mm2']=data['T']+0.5+data['Td']*0.1+np.random.normal(0, 1, data['T'].shape)
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2']])
Y=pd.DataFrame(data['wind'])
Y.loc[Y['wind']<10,'wind']=0
Y.loc[Y['wind']>0,'wind']=1
# Separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
test_size=0.3, random_state=0)
# set up the wrapper with the SimpleImputer
imputer = SklearnTransformerWrapper(transformer = SimpleImputer(strategy='mean'),
variables = ['T', 'Td'])
# fit the wrapper + SimpleImputer
imputer.fit(X_train)
# transform the data
X_train_t = imputer.transform(X_train)
X_test_t = imputer.transform(X_test)
StandardScaler
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2']])
Y=pd.DataFrame(data['wind'])
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
test_size=0.3, random_state=0)
# set up the wrapper with the StandardScaler
scaler = SklearnTransformerWrapper(transformer = StandardScaler(),
variables = ['T', 'Td'])
# fit the wrapper + StandardScaler
scaler.fit(X_train)
# transform the data
X_train_t = scaler.transform(X_train)
X_test_t = scaler.transform(X_test)
KBinsDiscretizer
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2']])
Y=pd.DataFrame(data['wind'])
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
test_size=0.3, random_state=0)
cols = [var for var in X_train.columns if X_train[var].dtypes !='O']
# let's apply the standard scaler on the above variables
selector = SklearnTransformerWrapper(
transformer = SelectKBest(f_regression, k=5),
variables = cols)
selector.fit(X_train.fillna(0), y_train)
# transform the data
X_train_t = selector.transform(X_train.fillna(0))
X_test_t = selector.transform(X_test.fillna(0))
Feature selectors
data=data1.copy()
data=data.drop(columns=['Hmdx'],axis=1) #drop NaN column
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01+np.random.normal(0, 1, data['T'].shape)
data['mm2']=data['T']+0.5+data['Td']*0.1+np.random.normal(0, 1, data['T'].shape)
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2']])
Y=pd.DataFrame(data['wind'])
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
test_size=0.3, random_state=0)
cols = [var for var in X_train.columns if X_train[var].dtypes !='O']
# let's select the best variables according to Lasso
lasso = Lasso(alpha=10000, random_state=0)
sfm = SelectFromModel(lasso, prefit=False)
selector = SklearnTransformerWrapper(
transformer = sfm,
variables = cols)
selector.fit(X_train.fillna(0), y_train)
Categorical encoder
keepcolumns=['Date/Time (LST)','Longitude (x)','Year', 'Month', 'Day','Temp (°C)',
'Dew Point Temp (°C)','Hmdx','Stn Press (kPa)','Wind Spd (km/h)','Weather']
data=df[keepcolumns]
data=data.rename(columns={'Longitude (x)':'Lat','Date/Time (LST)':'dt_var','Temp (°C)':'T','Dew Point Temp (°C)':'Td',
'Stn Press (kPa)':'ps','Wind Spd (km/h)':'wind'
})
data['mm']=data['Month']
data['mm1']=data['mm']+data['Day']*0.01+np.random.normal(0, 1, data['T'].shape)
data['mm2']=data['T']+0.5+data['Td']*0.1+np.random.normal(0, 1, data['T'].shape)
X=pd.DataFrame(data[['Lat', 'Year', 'Month', 'Day', 'T', 'Td', 'mm', 'mm1','mm2','Weather']])
Y=pd.DataFrame(data['wind'])
X_train, X_test, y_train, y_test = train_test_split(
X,
Y,
test_size=0.3, random_state=0)
# let's remove rare labels to avoid errors when encoding
cols=['Weather']
rare_label_enc = RareLabelEncoder(n_categories=2, variables=['Weather'])
X_train = rare_label_enc.fit_transform(X_train.fillna('Missing'))
X_test = rare_label_enc.transform(X_test.fillna('Missing'))
# now let's replace categories by integers
encoder = SklearnTransformerWrapper(
transformer = OrdinalEncoder(),
variables = cols,
)
encoder.fit(X_train,y_train)
X_train = encoder.transform(X_train)
X_test = encoder.transform(X_test)
X_train[cols].isnull().mean()
X_train['Weather'].unique()
#array([4, 1, 3, 0, 5, 2])
Pipeline
keepcolumns=['Date/Time (LST)','Longitude (x)','Year', 'Month', 'Day','Temp (°C)',
'Dew Point Temp (°C)','Hmdx','Stn Press (kPa)','Wind Spd (km/h)','Weather']
data=df[keepcolumns]
data=data.rename(columns={'Longitude (x)':'Lat','Date/Time (LST)':'dt_var','Temp (°C)':'T','Dew Point Temp (°C)':'Td',
'Stn Press (kPa)':'ps','Wind Spd (km/h)':'wind'
})
datetime_series = pd.to_datetime(data['dt_var'])
datetime_index = pd.DatetimeIndex(datetime_series.values)
data1=data.set_index(datetime_index)
data1.drop('dt_var',axis=1,inplace=True)
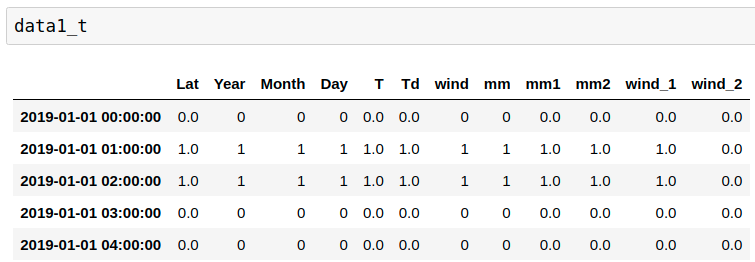
pipeline = Pipeline(steps = [
('weather', CategoricalImputer(imputation_method='frequent')),
('T', MeanMedianImputer(imputation_method='mean')),
('Td', OrdinalEncoder(encoding_method='arbitrary')),
('ps', SklearnTransformerWrapper(
PolynomialFeatures(interaction_only = True, include_bias=False),
variables=['T','Td','wind']))
])
pipeline.fit(data1)
data1_t = pipeline.transform(data1)