The sample code shows you how to encode categorical data and answer the following questions:
- How to perform one hot encoding with feature_engine?
- How to perform count frequency encoding with feature_engine?
- How to perform ordinal encoding with feature_engine?
- How to perform mean encoding with feature_engine?
Table of Contents
One hot encoder
Replaces the categorical variable by a group of binary variables which take value 0 or 1, to indicate if a certain category is present in an observation.
Example code
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from feature_engine.encoding import OneHotEncoder
# Load dataset
def load_titanic():
data = pd.read_csv('https://www.openml.org/data/get_csv/16826755/phpMYEkMl')
data = data.replace('?', np.nan) #replace ? with np.nan
data['cabin'] = data['cabin'].astype(str).str[0] #set cabin as string variable and take the first character as it's value
data['pclass'] = data['pclass'].astype('O') #set pclass as Ordinal Categorical variable
data['embarked'].fillna('C', inplace=True) #replace nan with 'C'
return data
data = load_titanic()
# Separate into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
data.drop(['survived', 'name', 'ticket'], axis=1),
data['survived'], test_size=0.3, random_state=0)
# set up the encoder
#! encode top 2 categories for 3 variables
encoder = OneHotEncoder(top_categories=2, variables=['pclass', 'cabin', 'embarked'])
# fit the encoder
#! generate encoder_dict_
encoder.fit(X_train)
# transform the data
train_t= encoder.transform(X_train)
test_t= encoder.transform(X_test)
Results of one hot encoder example:
encoder.encoder_dict_
{'pclass': [3, 1], 'cabin': ['n', 'C'], 'embarked': ['S', 'C']}

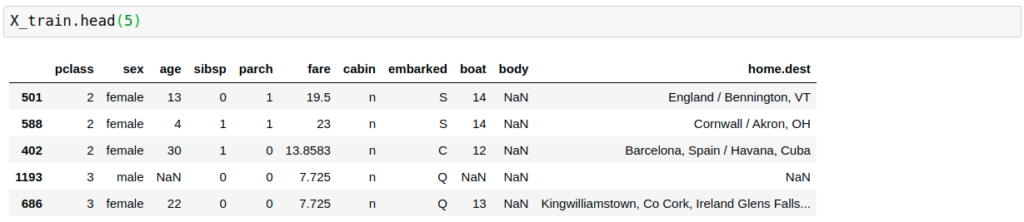
The top 2 categories:

The 6 new variables based on the top 2 categories:

Count Frequency Encoder
Replaces categories by either the count or the percentage of observations per category.
Example code (partial)
...
from feature_engine.encoding import CountFrequencyEncoder
# set up the encoder
encoder = CountFrequencyEncoder(encoding_method='frequency',
variables=['cabin', 'pclass', 'embarked'])
# fit the encoder
encoder.fit(X_train)
# transform the data
train_t= encoder.transform(X_train)
test_t= encoder.transform(X_test)
Some results
Frequency of each categories:

The category names are replaced by the frequency:

Ordinal Encoding
Replaces the categories by digits, starting from 0 to k-1, where k is the number of different categories.If you select “ordered”, the encoder will assign numbers following the mean of the target value for that label.
Example code
...
from feature_engine.encoding import OrdinalEncoder
# set up the encoder
encoder = OrdinalEncoder(encoding_method='ordered', variables=['pclass', 'cabin', 'embarked'])
# fit the encoder
encoder.fit(X_train, y_train)
# transform the data
train_t= encoder.transform(X_train)
test_t= encoder.transform(X_test)
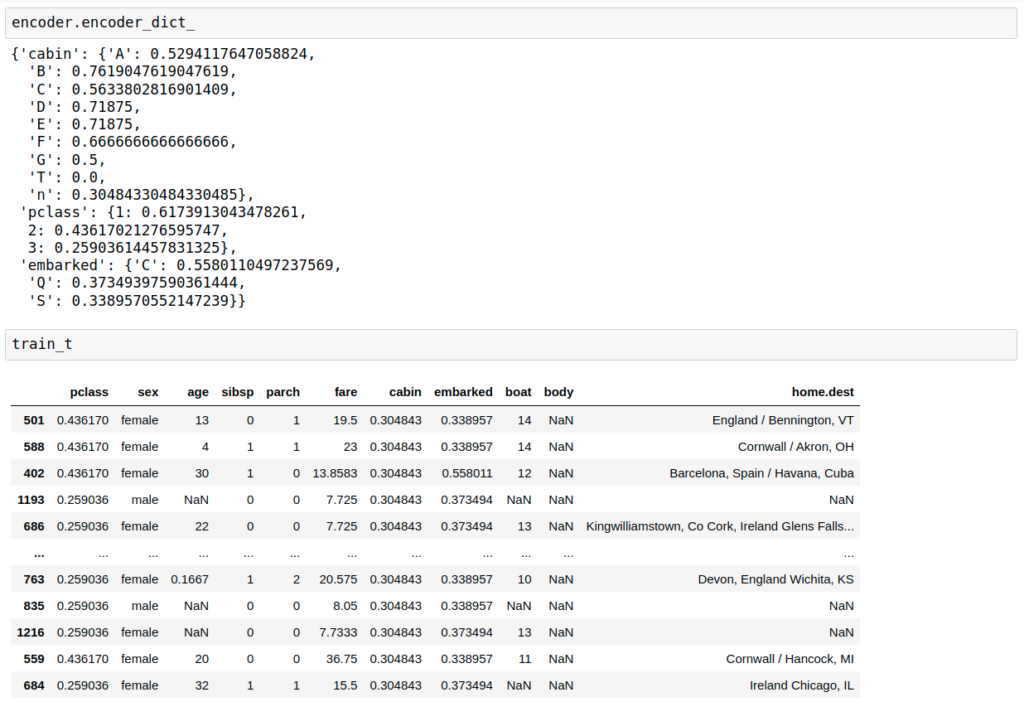
Results

Mean Encoding
Replaces categories with the mean of the target per category.
Example code
...
from feature_engine.encoding import MeanEncoder
# set up the encoder
# set up the encoder
encoder = MeanEncoder(variables=['cabin', 'pclass', 'embarked'])
# fit the encoder
encoder.fit(X_train, y_train)
# transform the data
train_t= encoder.transform(X_train)
test_t= encoder.transform(X_test)
Results
The row orders are the same as ordinal encoding but the variable values are replaced with the target variable’s mean values.
WoE encoding
Replaces categories by the weight of evidence (WoE).
Example code
category variables
...
from feature_engine.encoding import WoEEncoder, RareLabelEncoder
# set up the encoder
# set up a rare label encoder
rare_encoder = RareLabelEncoder(tol=0.03, n_categories=2, variables=['cabin', 'pclass', 'embarked'])
# fit and transform data
train_t0 = rare_encoder.fit_transform(X_train)
test_t0 = rare_encoder.transform(X_train)
# set up a weight of evidence encoder
woe_encoder = WoEEncoder(variables=['cabin', 'pclass', 'embarked'])
# fit the encoder
woe_encoder.fit(train_t0, y_train)
# transform
train_t = woe_encoder.transform(train_t0)
test_t = woe_encoder.transform(test_t0)
Results
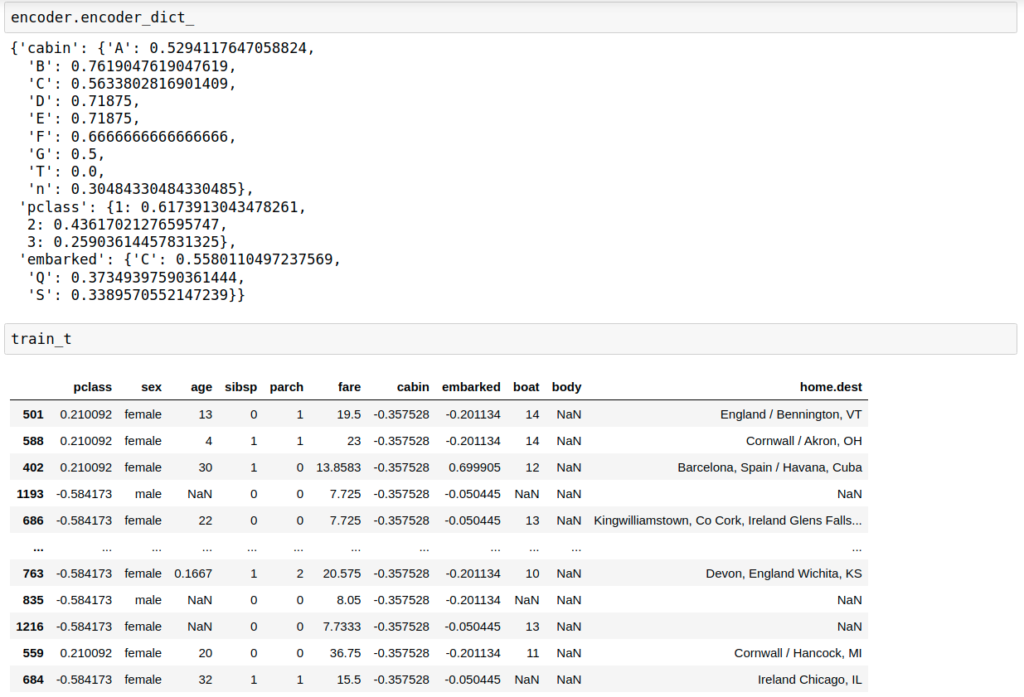
Continuous variables
Discrete number into bins, then encode the categories.
Other encoding methods:
- PRatioEncoder:https://feature-engine.readthedocs.io/en/latest/user_guide/encoding/PRatioEncoder.html#
- DecisionTreeEncoder:https://feature-engine.readthedocs.io/en/latest/user_guide/encoding/DecisionTreeEncoder.html
- RareLabelEncoder:https://feature-engine.readthedocs.io/en/latest/user_guide/encoding/RareLabelEncoder.html
- StringSimilarityEncoder:https://feature-engine.readthedocs.io/en/latest/user_guide/encoding/StringSimilarityEncoder.html
Note: For my personal reference while working on feature engineering.
