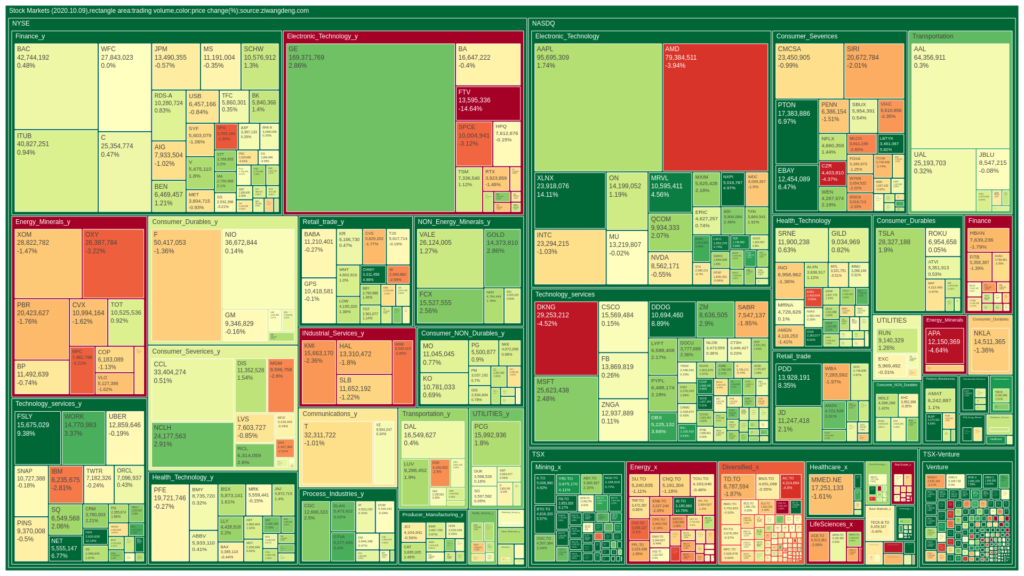
Sample code for multiple-level treemap generation.This example also includes some methods on pandas data processing, such as:
- How to create a pandas dataframe?
- How to append several dataframe to construct a bigger dataframe?
- How to build a hierarchical dataframe?
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
from datetime import datetime
now = datetime.now()
current_Year=now.strftime("%Y")
current_Month=now.strftime("%m")
current_day=now.strftime("%d")
current_hour = now.strftime("%H")
todayDay=current_Month+current_day
def build_hierarchical_dataframe(df, levels, value_column, color_columns=None):
"""
Build a hierarchy of levels for Sunburst or Treemap charts.
Levels are given starting from the bottom to the top of the hierarchy,
ie the last level corresponds to the root.
"""
df_all_trees = pd.DataFrame(columns=['id', 'parent', 'value', 'color','text'])
for i, level in enumerate(levels):
df_tree = pd.DataFrame(columns=['id', 'parent', 'value', 'color'])
dfg = df.groupby(levels[i:]).sum()
dfg = dfg.reset_index()
df_tree['id'] = dfg[level].copy()
if i < len(levels) - 1:
df_tree['parent'] = dfg[levels[i+1]].copy()
else:
df_tree['parent'] = ''
df_tree['value'] = dfg[value_column]
df_tree['color'] = dfg[color_columns]
df_tree['text']=dfg[color_columns].astype(str)+'%'
df_all_trees = df_all_trees.append(df_tree, ignore_index=True)
total = pd.Series(dict(id='', parent='',
value=df[value_column].sum(),
color=df[color_columns].mean()))
df_all_trees = df_all_trees.append(total, ignore_index=True)
return df_all_trees
fnlist='TSXinCanadaMostActiveStocks_Sectors.txt'
fns=pd.read_csv(fnlist)
path3='TSXTO/'
#? how to generate a empty dataframe?
tsxdata=pd.DataFrame(columns={'Date':[],
'Stock':[],
'Sector':[],
'Open':[],
'High':[],
'Low':[],
'Close':[],
'Change(%)':[],
'Adj Close':[],
'Volume':[]})
for fn0 in fns.Symbols:
stockName=fn0.replace(' ','')
tdfn=path3 + fn0 + '.csv'
tdfn=tdfn.replace(' ','')
tddata=pd.read_csv(tdfn)
tddata=tddata.dropna()
if(tddata.shape[0]==2):
tddata=tddata[-2:]
Sector=fns[fns.Symbols==fn0]
theSector=Sector['Sector'].iloc[0]+'_x'
priceChange=np.round((tddata.Close.iloc[1]/tddata.Close.iloc[0]-1)*100,2)
#? how to generate a 1-row dataframe?
todayData=pd.DataFrame({'Date':tddata.Date.iloc[1],
'Stock':stockName,
'Sector':theSector,
'Open':tddata.Open.iloc[1],
'High':tddata.High.iloc[1],
'Low':tddata.Low.iloc[1],
'Close':np.round(tddata.Close.iloc[1],2),
'Change(%)':priceChange,
'Adj Close':tddata['Adj Close'].iloc[1],
'Volume':np.round(tddata.Volume.iloc[1],0)
},index=[0])
tsxdata=tsxdata.append(todayData,ignore_index=True)
else:
continue
tsxdata['NorthAmerica']='NorthAmerica'
tsxdata['Market']='TSX'
tsxdata=tsxdata[tsxdata.Close>0.1]
tsxdata['MF']=(tsxdata.Close+tsxdata.Low +tsxdata.High)/3.0 * tsxdata.Volume
tsxdata=tsxdata.sort_values('MF', ascending=False)
tsxdata=tsxdata.drop_duplicates()
tsxdata=tsxdata.head(200)
fnlist='nasdqIntheUSAMostActiveStocks_Sectors.txt'
fns=pd.read_csv(fnlist)
path3='NASDQ/'
nasdqdata=pd.DataFrame(columns={'Date':[],
'Stock':[],
'Sector':[],
'Open':[],
'High':[],
'Low':[],
'Close':[],
'Change(%)':[],
'Adj Close':[],
'Volume':[]})
for fn0 in fns.Symbols:
stockName=fn0.replace(' ','')
#print(stockName)
tdfn=path3 + fn0 + '.csv'
tdfn=tdfn.replace(' ','')
tddata=pd.read_csv(tdfn)
tddata=tddata.dropna()
Sector=fns[fns.Symbols==fn0]
theSector=Sector['Sector'].iloc[0]
if(tddata.shape[0]==2):
tddata=tddata[-2:]
priceChange=np.round((tddata.Close.iloc[1]/tddata.Close.iloc[0]-1)*100,2)
todayData=pd.DataFrame({'Date':tddata.Date.iloc[1],
'Stock':stockName,
'Sector':theSector,
'Open':tddata.Open.iloc[1],
'High':tddata.High.iloc[1],
'Low':tddata.Low.iloc[1],
'Close':np.round(tddata.Close.iloc[1],2),
'Change(%)':priceChange,
'Adj Close':tddata['Adj Close'].iloc[1],
'Volume':np.round(tddata.Volume.iloc[1],0)
},index=[0])
nasdqdata=nasdqdata.append(todayData,ignore_index=True)
else:
continue
nasdqdata['NorthAmerica']='NorthAmerica'
nasdqdata['Market']='NASDQ'
nasdqdata['MF']=(nasdqdata.Close+nasdqdata.Low+nasdqdata.High)/3.0 * nasdqdata.Volume
nasdqdata=nasdqdata[nasdqdata.Close>0.1]
nasdqdata=nasdqdata.sort_values('MF', ascending=False)
nasdqdata=nasdqdata.drop_duplicates()
nasdqdata=nasdqdata.head(200)
fnlist='nyseIntheUSAMostActiveStocks_Sectors.txt'
fns=pd.read_csv(fnlist)
path3='NYSE/'
nysedata=pd.DataFrame(columns={'Date':[],
'Stock':[],
'Sector':[],
'Open':[],
'High':[],
'Low':[],
'Close':[],
'Change(%)':[],
'Adj Close':[],
'Volume':[]})
for fn0 in fns.Symbols:
stockName=fn0.replace(' ','')
#print(stockName)
tdfn=path3 + fn0 + '.csv'
tdfn=tdfn.replace(' ','')
tddata=pd.read_csv(tdfn)
tddata=tddata.dropna()
Sector=fns[fns.Symbols==fn0]
theSector=Sector['Sector'].iloc[0]+'_y'
if(tddata.shape[0]==2):
tddata=tddata[-2:]
priceChange=np.round((tddata.Close.iloc[1]/tddata.Close.iloc[0]-1)*100,2)
todayData=pd.DataFrame({'Date':tddata.Date.iloc[1],
'Stock':stockName,
'Sector':theSector,
'Open':tddata.Open.iloc[1],
'High':tddata.High.iloc[1],
'Low':tddata.Low.iloc[1],
'Close':np.round(tddata.Close.iloc[1],2),
'Change(%)':priceChange,
'Adj Close':tddata['Adj Close'].iloc[1],
'Volume':np.round(tddata.Volume.iloc[1],0)
},index=[0])
nysedata=nysedata.append(todayData,ignore_index=True)
else:
continue
nysedata['NorthAmerica']='NorthAmerica'
nysedata['Market']='NYSE'
nysedata['MF']=(nysedata.Close+nysedata.Low+nysedata.High)/3.0 * nysedata.Volume
nysedata=nysedata[nysedata.Close>0.1]
nysedata=nysedata.sort_values('MF', ascending=False)
nysedata=nysedata.drop_duplicates()
nysedata=nysedata.head(200)
fnlist='VentureStocksInCanadaMostActiveStocks.txt'
fns=pd.read_csv(fnlist)
path3='TSXV/'
venturedata=pd.DataFrame(columns={'Date':[],
'Stock':[],
'Sector':[],
'Open':[],
'High':[],
'Low':[],
'Close':[],
'Change(%)':[],
'Adj Close':[],
'Volume':[]})
for fn0 in fns.Symbols:
stockName=fn0.replace(' ','')
#print(stockName)
tdfn=path3 + fn0 + '.csv'
tdfn=tdfn.replace(' ','')
tddata=pd.read_csv(tdfn)
tddata=tddata.dropna()
Sector=fns[fns.Symbols==fn0]
theSector='Venture'
if(tddata.shape[0]==2):
tddata=tddata[-2:]
priceChange=np.round((tddata.Close.iloc[1]/tddata.Close.iloc[0]-1)*100,2)
todayData=pd.DataFrame({'Date':tddata.Date.iloc[1],
'Stock':stockName,
'Sector':theSector,
'Open':tddata.Open.iloc[1],
'High':tddata.High.iloc[1],
'Low':tddata.Low.iloc[1],
'Close':np.round(tddata.Close.iloc[1],2),
'Change(%)':priceChange,
'Adj Close':tddata['Adj Close'].iloc[1],
'Volume':np.round(tddata.Volume.iloc[1],0)
},index=[0])
venturedata=venturedata.append(todayData,ignore_index=True)
else:
continue
venturedata['NorthAmerica']='NorthAmerica'
venturedata['Market']='TSX-Venture'
venturedata['MF']=(venturedata.Close+venturedata.Low+venturedata.High)/3.0 * venturedata.Volume
venturedata=venturedata[venturedata.Close>0.1]
venturedata=venturedata.sort_values('MF', ascending=False)
venturedata=venturedata.drop_duplicates()
venturedata=venturedata.head(150)
#? how to combine serveral dataframe to a bigger dataframe?
df=tsxdata.append(nasdqdata,ignore_index=True). .append(nysedata,ignore_index=True).append(venturedata,ignore_index=True)
df['NorthAmerica']='Stock Markets ('+ current_Year +'.'+current_Month +'.' +current_day+'),rectangle area:trading volume,color:price change(%);source:ziwangdeng.com'
levels = ['Stock','Sector','Market','NorthAmerica'] # levels used for the hierarchical chart
color_columns = 'Change(%)'
df.loc[df['Volume']==0,'Volume']=1
value_column = 'Volume'
df_all_trees = build_hierarchical_dataframe(df, levels, value_column, color_columns)
average_score = 0
#? how to generate a treemap?
fig = go.Figure()
fig.add_trace(go.Treemap(
labels=df_all_trees['id'],
parents=df_all_trees['parent'],
values=df_all_trees['value'],
text=df_all_trees['text'],
branchvalues='total',
marker=dict(
colors=df_all_trees['color'],
colorscale='rdylgn',
cmin=-5,
cmax=5,
cmid=0),
#hovertemplate='<b>%{label} </b> <br> Change: %{value}%<br> Change: %{color:.2f}%',
#maxdepth=5
))
fig.data[0].textinfo = 'label + value + text'
fig.layout.hovermode = False
fig.update_layout(margin=dict(t=10, b=10, r=10, l=10),height=1920,width=1080)
fig.show()
fig.write_image('NA_MarketSummary/NorthAmericaMarket.svg')
fig.write_image('NA_MarketSummary/NorthAmericaMarket.png')
fig.write_html('NA_MarketSummary/VolumePricePercent/MarketSummary.html')